When you are planning to run BOINC on a Kubernetes Raspbery Pi cluster there are e few things you have to keep in mind.
Persistence
Kubernetes will run the BOINC-client in a so called Pod. This is actually the container of your application. Each Pod has an dedicated amount of CPU, RAM and diskspace. Pods are stateless. This means the Kubernetes system will restart or recreate your Pod on certain conditions like a crash. If this happens, all the data inside the Pod is lost. Recreation will always be from scratch with a fresh copy from your containerd image repository. The consequences for you BOINC-client are
- Progress on your active tasks are lost (and reported as canceled to the BOINC project)
- Downloaded and stored „ready to start“ tasks are lost (and reported as canceled to the BOINC project)
- After restart all your projects need to be reattached to the BOINC-client
- Usage of account managers like BOINCstats!BAM needs to be recreated
- Work preferences need to be restored
- Computer location needs to be set again
To prevent this issues you can define a certain directory which can be enabled by setting the option --dir /your/work/dir when the BOINC-client is started. You need also to define this certain directory in your deployment manifest as a PersistentVolume.
Accessibility
Do you want to run 4 small pods simultaneously with 1 assigned CPU each or do you want to run a big pod with 4 CPUs assigned on each node of your cluster? This might depend on the capabilities of your Raspberry Pi nodes ( 2 / 4 / 8 GB of RAM). The Kubernetes philosophy assures that each pod within your deployment runs the identical application. If your deployment manifest requests 4 replicas for you application each pod is part of a replica set. Now imagine you have 4 BOINC pods per node running and you want to check crunching progress from you Desktop or Laptop using the BOINC-Manager. How to connect to Pod 3 on Node 2 since you have defined an the same remote_gui_rpc port for your container?
It is simply not possible. Per Kubernetes default its not intended that you can access your pod from outside the cluster. Shure you can open a shell to a running pod but thats not comfortable and more for debugging. There a several ways to expose your application outside the cluster with a so called service definition in your manifest. Usually – or most common – a loadbalancer is used to forward external requests to the pods ( and application ). A use case here might be a huge Website with a lot of traffic. This Website might run on 20 pods distributed over 4 nodes. With a loadbalancer service you don’t need to worry about IPs or Ports to access the site. Kubernetes will handle that for you and always deliver a webpage if you connect to your cluster, even if one of these nodes are down.
So you how to connect to a certain BOINC-client in a pod using BOINC Manager from a Desktop? For me the only suitable way was to define one pod per cluster node in K3S. With the nodePort Argument in the service definition exactly one port per node is exposed which forwards the traffic to to pod on each node itself (this port suprisingly is the boinc rpc port).
armv64 specific
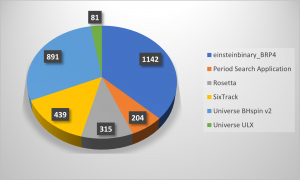
As far as i know Rosetta@Home, LHC@Home and WCG are supporting armv64 CPUs nativly. I’d also like to try Asteriods@Home but one of their main servers broke down which could not be replaced within the pandemic yet. There is an official project list where you can check armv64 support for your favorite projects.
I am volunteering for Einstein@Home since 2009. The projects also support ARM CPUs but I never got tasks on the K3S cluster initially. Later I found out that the Einstein@Home ARM software version is not distributed by attaching Einstein to your client. You have to download and copy the binaries before you attach the project manually on a Raspberry Pi. Here you find the installation instructions. Now the Raspberry Pi is also crunching Einstein tasks.
BOINC specific
The main bottlenecks are described above. These are mostly caused because we use Kubernetes K3S as a platform. I am also volunteering on my Desktop and therefore I need different work preferences than on the Raspberry Pi. You can define separate work preferences for computer locations ( work / home / school ) but I was still not able to set the computer location per command line for the Raspberry Pi. Actually I had to define that manually. Each of your computers are mapped to a working preset by its computer name. The desktop has a static name, but the Raspberry Pi are registering with their pod name have a random part (showed green):
pi@pik3s-m01:~ $ sudo kubectl get pods --namespace boinc
NAME READY STATUS RESTARTS AGE
rosettaathome-6488955db4-85tkl 1/1 Running 2 24d
rosettaathome-6488955db4-dx9ds 1/1 Running 2 24d
rosettaathome-6488955db4-zq8pv 1/1 Running 3 24d
rosettaathome-6488955db4-vk847 1/1 Running 35 24d
So if you recreate your pods often you will end up in a lot of computers volunteering to the project. You have to consolidate old and now longer existent Computers (Pods in our case) in your projects account manually.